
This technique allows for real-time rendering scenes in 3D
Humans can see a single image in two dimensions and understand the entire scene. Artificial intelligence agents aren’t as good.
However, a machine that interacts with the world, such as a robot to harvest crops or perform surgery, must be able infer properties from the 2D images it has seen.
Although neural networks have been used by scientists to derive 3D scenes from images, they aren’t fast enough for many real-world applications.
Researchers at MIT and other institutions have demonstrated a new method that can render 3D scenes from images approximately 15,000 times faster then existing models.
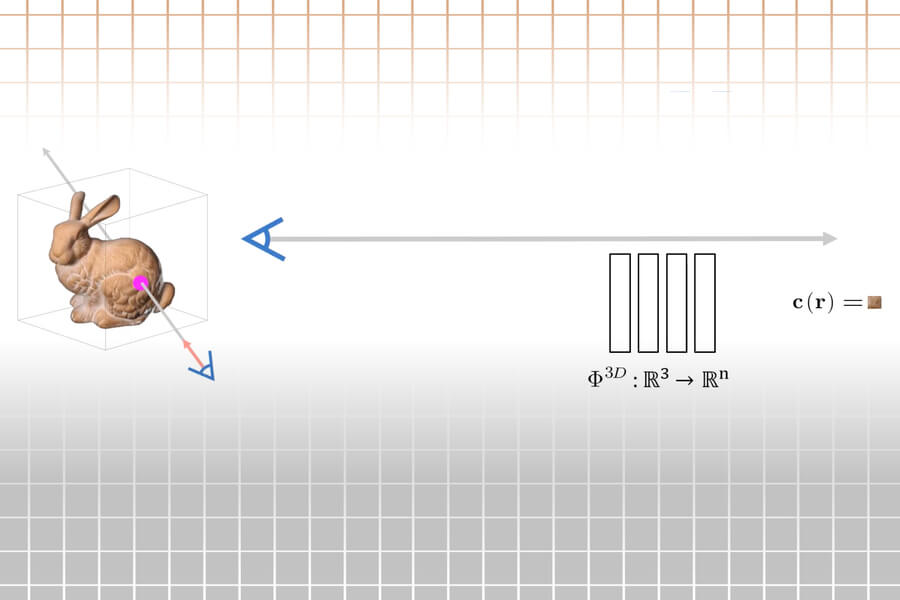
This method depicts a scene as an 360-degree lightfield, which is a function that describes all light rays flowing through a 3D space. This encodes the light field into a neural network which allows faster rendering of the 3D scene from an original image.
Researchers developed light-field networks (LFNs), which can reconstruct a lightfield from a single image. They are capable of rendering 3D scenes at real time frame rates.
The big promise of neural scene representations is their ability to be used in vision tasks. Vincent Sitzmann is a postdoc at the Computer Science and Artificial Intelligence Laboratory, (CSAIL), and co-lead writer of the paper.
Sitzmann co-authored the paper with Semon Rezchikov (a Harvard University postdoc); William T. Freeman (the Thomas and Gerd Perkins Prof of Electrical Engineering and Computer Science and a Member of CSAIL); Joshua B. Tenenbaum (a professor of computational cognition science in the Department of Brain and Cognitive Sciences and a Member of CSAIL); and Fredo Durand (a senior author and a Professor of Electrical Engineering and Computer Science and a Member of CSAIL). This month, the research will be presented at Conference on Neural Information Processing Systems.
Mapping Rays
Computer vision and computer graphics require the mapping of thousands to millions of camera rays in order to create a 3D scene out of an image. Camera rays can be thought of as laser beams that shoot out from a camera lens striking every pixel in an image with one ray perpixel. These computer models need to determine the color of each pixel that is struck by a camera ray.
Current methods achieve this by taking hundreds upon hundreds of samples as the camera ray moves through space. This is computationally costly and can result in slow rendering.
An LFN instead learns how to represent the 3D scene’s light field and maps each camera ray within the light field to the color being observed by that particular ray. An LFN uses the unique properties inherent to light fields to render rays after only one evaluation. This means that calculations can be run without stopping at any point along the length of the ray.
“With other methods, you must follow the rays until you find the surface. Because it is necessary to find a surface, you will need to take thousands of samples. You may need to do more complex things such as reflections or transparency. Sitzmann says that once you have created a light field, which can be a complex problem, rendering one ray takes only one sample of the representation. The representation maps a ray directly to its color.
Each camera ray is classified by the LFN using its “Plucker Coordinates,” which are 3D coordinates that represent a line in 3D space. These coordinates indicate its direction and distance from its origin. To render an image, the system calculates the Plucker coordinates for each camera ray at its point of impact with a pixel.
The parallax effect allows the LFN to map each ray using Plucker coordinates. Parallax refers to the apparent difference in position between two lines of sight. If you move your head, objects farther away will appear to move more than objects closer. Parallax can be used by the LFN to determine the depth of objects within a scene. This information is used to encode the geometry and appearance of a scene.
To reconstruct light fields, however, the neural network must first understand the structure of light fields. Therefore, researchers trained their model using images of simple cars and chairs.
“There is an intrinsic geometry to light fields. This is what our model is trying learn. It might be a concern that the light fields of chairs and cars are so different that there is no way to learn commonality. Rezchikov says that if you add more objects, as long there is some homogeneity you get a better idea of how light fields look of general objects. This allows you to generalize about classes.
After learning the structure of a lightfield, the model can create a 3D scene using only one image.
Rapid rendering
Researchers tested the model by constructing 360-degree light fields from simple scenes. LFNs could render scenes at over 500 frames per second, which is three orders of magnitude faster that other methods. LFNs also rendered 3D objects at a higher resolution than other models.
LFNs are also less memory-intensive than the popular baseline method, which requires 146 megabytes.
Although light fields have been proposed before, they were difficult to model back then. These techniques, which we present in this paper, allow you to both represent and work with light fields. Sitzmann states that it is an interesting convergence between the mathematical models and neural network models we have created in this application of representing scenes for machines to reason about them.
The researchers hope to improve the model’s stability so that it can be used in complex real-world scenes. Sitzmann states that LFNs can be improved by focusing on reconstructing specific patches of the light fields. This will allow the model to run more quickly and perform better in real-world settings.